

DeciLM-7B Dethrones Mistral-7B on the Open LLM Leaderboard
Resources to help to you get started with the model

What’s up, community!
It’s been a while since we’ve connected, but I’m back with some exciting news to share👇🏽
I’ll keep this edition short so you can start experimenting with the model ASAP - here's what you need to get started:
📔DeciLM-7B Base Model Notebook: https://bit.ly/decilm-7b-notebook
📘DeciLM-7B Fine-tuning Notebook: https://bit.ly/decilm-7b-finetune
📗DeciLM-7-Instruct Notebook: https://bit.ly/declm-7b-instruct
Help us get trending on HuggingFace by ❤️ the model cards
🤗 Base model: https://huggingface.co/Deci/DeciLM-7B
🤗 Instruction-tuned model: https://huggingface.co/Deci/DeciLM-7B-instruct
🤗 Demo on HF Spaces: https://huggingface.co/spaces/Deci/DeciLM-7B-instruct
👀Check out DeciLM + Infery: https://hubs.ly/Q02cz_pB0
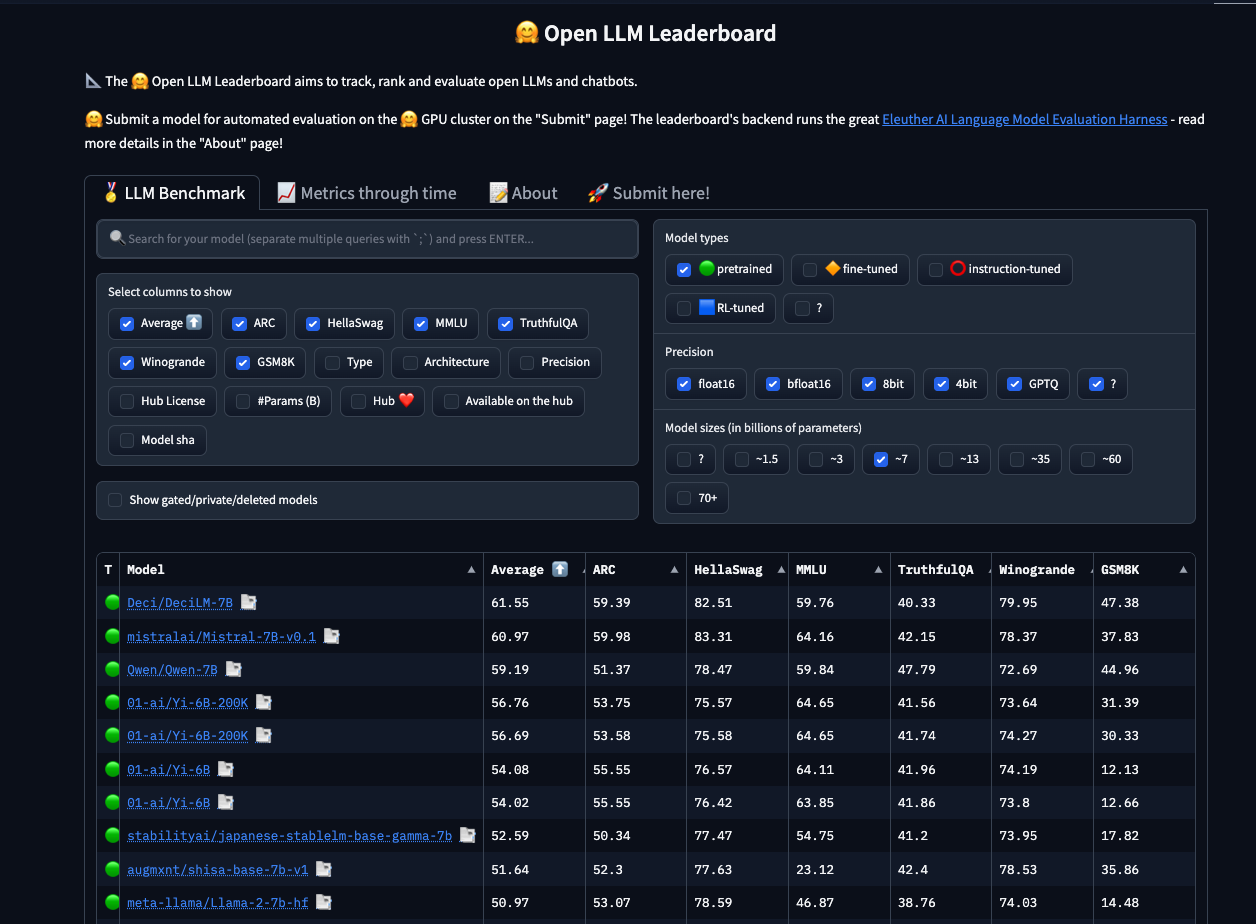
⭐️ Bonus resource: Evaluating DeciLM-7B vs Mistral-7B on Chain of Thought prompts
Note: I finished this notebook yesterday before learning about the news Mistral model. I will re-run this with the new Mistral instruct-tuned model later this week. If anyone from the community wants to re-run the notebook using the new Mistral model before then, please do.
📘 Check the notebook out here
🧐 What I'm doing
I sampled 30 random rows from the kaist-ai/CoT-Collection. This dataset is 1M+ rows, so it was infeasible for me to use them all. I chose 30 because, once upon a time, I was a clinical trials statistician, and 30 was always a magical number.
I then generated responses for each prompt under a zero, one, and three-shot setting for DeciLM-7B-Instruct and Mistral-7B-v01.
⚖️ 👩⚖️ Evaluations - LLM as Judge
I used LangChain string evaluators for the following, with GPT-4-Turbo as judge.
COT Evaluation (evaluate_cot): This grades answers to questions using chain of thought 'reasoning' based on a reference answer. It will return one of the following evaluation results: CORRECT or INCORRECT, evaluating whether the generation is correct, accurate, and factual.
Coherence Evaluation (evaluate_coherence): This gives a score between 1 and 10 to the generation, assessing whether it is coherent, well-structured, and organized based on a ground truth reference label. This is useful for assessing the quality of the generation's reasoning.
Faithfulness via ragas
I also used the ragas framework to measure faithfulness, which assesses how well a model's responses align with the given context or source material. This was also done using GPT-4-Turbo
🤷🏽♂️Why did I do this?
Mostly because I'm curious and thought it would be a cool project. I also work at Deci, and I'm skeptical of benchmarks and wanted to see if our model was as good as we claim.
All feedback is welcome. Enjoy!
I’ll get back to the usual Friday editions starting this week. Keep an eye out for our regularly scheduled newsletters!
Cheers,
Harpreet
Great community. Hope to learn and contribute from it
Thanks for sharing!
I will definitely try it now and give it a like 🤓.