



Decoding the Enigma: The Unpredictable Evolution of ChatGPT's Behavior
Plus: This Summer's virtual event calendar, the Sherry Code, Deci Digest, and papers worth reading

What’s up, community!
I’ve got some awesome events lined up for you this quarter! Here’s a preview of what’s going on over the next few months:
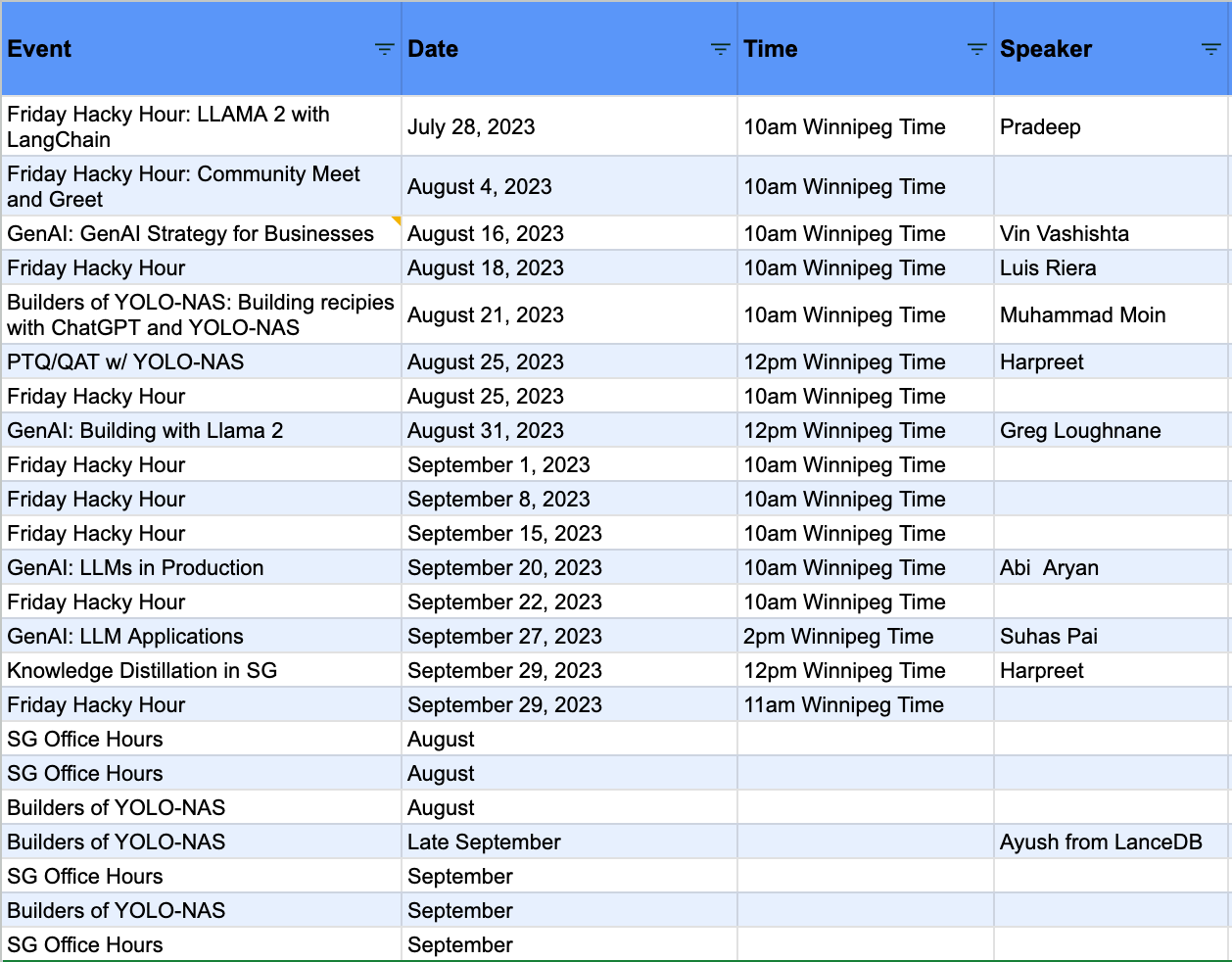
A lot of the events will be focused on Generative AI use cases. I want these sessions to be as practical as possible, so they’re focused on either building an application or addressing challenges and opportunities from a business and production perspective.
As you can see, I’ve got open slots for Friday Hacky Hour and the Builders of YOLO-NAS series. If you want to show off something you’ve done, reply to this email and let me know. I’ll schedule something up with you.
I’ll have registration links for all these events by the next newsletter, and I’ll be sure to remind you of the events the week of.
But you can always stay up on all events by hanging out in Discord 👇🏽
🧐 What’s in this edition?
🗞️ The Sherry Code (News headlines)
🤨 Unravelling the Mystery: Why is ChatGPT's Behavior Changing Over Time?(Opinion)
📰 The Deci Digest (Research and repositories)
📄 Paper Picks
🗞️ The Sherry Code: Your Weekly AI Bulletin
Shout out to Sherry for sharing her top picks for the AI news headlines you need to know about!
Sherry is an active member of the community. She’s at all the events, shares resources on Discord, and is an awesome human being.
Show some support and follow her on Instagram, Twitter, and Threads.
Claude 2 has been released by Anthropic. This upgraded AI model surpasses Claude 1.3 in coding, math, Bar exam scores, and evaluations such as HumanEval and GSM8k. It can handle up to 100K tokens for larger texts.
Google’s Bard has been updated and is now accessible worldwide and comes with added features such as the ability to support multiple languages, listen to responses, and customize output styles. Additionally, users can now pin conversations, export Python code, share responses, and integrate with Google Lens images. These updates make our platform more versatile and accessible to users across different countries.
OpenAI and Shutterstock have formed a partnership to collaborate on generative AI and artist compensation. As part of this deal, OpenAI will be using Shutterstock's media library to train their AI models. In exchange, Shutterstock will have priority access to OpenAI's image transformation tools. This expanded deal will enable both companies to enhance their services with the help of AI-powered tools.
NotebookLM: How to try Google’s experimental AI-first notebook. Google's NotebookLM merges Drive documents with LLMs, creating summaries, identifying key topics, suggesting questions, and aiding AI professionals with document management and idea generation.
A recent study by Stanford has shown that AI text detectors tend to discriminate against non-native English speakers. The study found that over 50% of essays written by non-native speakers were wrongly flagged as AI-generated, which is a cause for concern as it may affect their applications and well-being.
Why is ChatGPT's Behavior Changing Over Time?
In the ever-evolving world of AI, a new debate is causing quite a stir: Is ChatGPT losing its edge? Or is it just going through its 'teenage years'?
This discussion was sparked by a paper titled "How Is ChatGPT's Behavior Changing over Time?". But what does the paper really say, and what does it mean for us as users or developers of AI models?
Let's dive in.
The paper, authored by Lingjiao Chen, Matei Zaharia, and James Zou, suggests significant changes in the behaviour of GPT-4 and ChatGPT over time, including large decreases in some problem-solving tasks. However, as Arvind Narayanan points out in his commentary, these changes reflect a shift in behaviour, not a reduction in capability.
This distinction between capability and behaviour is crucial. As explained in the newsletter, chatbots acquire their capabilities through pre-training, a process that is expensive and time-consuming, and their behaviour is heavily influenced by fine-tuning, which is cheaper and done regularly.
So, while a model's behaviour can vary substantially over time, its capabilities should remain largely the same.
Capabilities in AI models like ChatGPT are the fundamental abilities acquired during the initial, extensive training phase. They are generally stable and don't change significantly over time.
Behaviours are how the AI model applies its capabilities in response to specific tasks. They are influenced by the fine-tuning process, which can introduce variability and unpredictability, causing the model's behaviour to vary over time.
In the context of ChatGPT, the capabilities would refer to its ability to understand and generate human-like text. In contrast, its behaviours refer to how it responds to specific prompts or tasks, such as generating code or solving math problems.
But here's where things get interesting.
If the capabilities remain the same, why are we seeing such drastic changes in behaviour? Is the fine-tuning process, while intended to improve the model's performance, actually introducing variability and unpredictability?
This is a hypothesis that's worth exploring.

What's more, these changes in behaviour can have significant implications for users and developers.
As Narayanan suggests, the user impact of behaviour change and capability degradation can be very similar. Users develop specific workflows and prompting strategies that work well for their use cases. When there is a behaviour drift, those workflows might stop working. This can be particularly challenging for applications built on the GPT API, as code deployed to users might break if the model underneath changes its behaviour.
So, is GPT-4 getting dumber?

The answer is no, at least not regarding its capabilities. But its behaviour changes, which can significantly affect users and developers. As we continue to use and develop AI models, we must be aware of these potential shifts and adapt our strategies accordingly.
Here's an "out there" hypothesis: Could these behaviour changes be a form of AI adolescence?
Like a teenager, the model is growing and changing, sometimes unpredictable. It's learning from its interactions, making mistakes, and sometimes rebelling against its training. It's a wild idea, but it's food for thought.
But what do the experts say?
Matei Zaharia, one of the paper's authors and CTO at Databricks confirmed that the study found significant changes in GPT-4 and ChatGPT behaviour over time. Gary Marcus, a known critic of current AI methodologies, interprets these results as a significant issue for LLMs, suggesting a need for more stable approaches to AI. Pietro Schirano, another AI expert, replicated all the cases presented in the study, suggesting that the findings are reliable and can be reproduced in different settings.
What are your thoughts on this? Have you noticed any changes in the behaviour of GPT-4 or ChatGPT? How have these changes affected your use or development of AI models?
Let's continue the conversation, reply to this email!
Webinar: How We Built YOLO-NAS - The Making of a Foundation Model with Neural Architecture Search
When: Wednesday, July 26, 2023 @ 11:00 am PST

Join Yonatan Geifman, CEO and Co-Founder of Deci AI, to learn how we brought to life the world's fastest object detection foundation model - YOLO-NAS.
What You'll Learn:
Explore the advanced techniques used in the design and training processes of YOLO-NAS.
Deep dive into Neural Architecture Search: Understand NAS's practical applications and potential, and how it is reshaping the realm of computer vision and Generative AI.
Participate in engaging Q&A sessions: This is your chance to get your questions answered directly by the trailblazers of Deci.ai.
📰 The Deci Digest
🦙 Meta open-sources LLaMa 2, its LLM with Microsoft, The Verge reports. Free for commercial and research use, the move is a way to encourage experimentation as a community by giving enterprises, startups, and researchers access to more AI tools. Read more about LLaMA from Meta AI.
🍏 From TechCrunch: Apple is testing a #ChatGPT-like AI chatbot. Having an internal foundation for creating large language models called Ajax, a small team of engineers has built a chatbot that is internally called “Apple GPT.”
🖼️ Researchers from NVIDIA, the University of Toronto, The Vector Institute, and MIT introduce DreamTeacher, a framework for self-supervised representation learning that uses generative models to downstream image backbones.
🦎 VentureBeat shares another piece of news from MetaAI. The company reveals its latest GenerativeAI model called CM3leon, a multimodal foundation model which can do both text-to-image and image-to-text generation. Learn more about CM3leon from Meta’s blog.
📹 Julian Bilcke from HuggingFace shares an article on building an AI WebTV using open-source text-to-video models such as Zeroscope and MusicGen. It showcases the latest advancements in automatic video and music synthesis.
📄 Paper Picks
I’m a fan of the
by Elvis, it’s been my go-to source for finding the right papers to read. The following are a few of the papers he’s selected:1) Llama 2
The paper introduces Llama 2, a collection of large language models fine-tuned for dialogue applications. These models range from 7 billion to 70 billion parameters. They outperform most open-source chat models on tested benchmarks and could replace closed-source models. The authors used techniques like context distillation and supervised safety fine-tuning (discussed in Section 3.1 of the paper) to improve the model's responses to adversarial prompts.
FlashAttention-2
The paper presents FlashAttention-2, an improved algorithm for the attention mechanism in Transformer models. This algorithm improves memory efficiency and speed on hardware accelerators such as GPUs. By dividing the workload between GPU warps and scheduling thread blocks more efficiently, FlashAttention-2 reduces shared memory reads and writes, resulting in faster computation. Empirical tests demonstrate that FlashAttention-2 performs significantly better than the original FlashAttention and a standard PyTorch implementation, particularly for longer sequences.
Meta-Transformer
The Meta-Transformer is a unified framework for multimodal learning that uses the same backbone to encode various types of data, including natural language, images, audio, video, and more. It aims to address the challenge of designing a unified network for processing multiple modalities by leveraging a frozen encoder. The framework has the potential for unified multi-modal intelligence.
Retentive Network
The paper introduces the Retentive Network (RETNET), a foundational architecture for large language models. RETNET is designed to achieve efficient parallel training, low-cost inference, and high performance. It features a retention mechanism for sequence modelling that supports parallel, recurrent, and chunkwise recurrent computation paradigms. Compared to the Transformer, RETNET has shown superior scaling results and the ability for parallel training, low-cost deployment, and efficient inference. The authors believe that RETNET could be an excellent replacement for the Transformer regarding large language models.
Challenges & Application of LLMs
This paper discusses the challenges and applications of LLMs. The challenges include dealing with vast datasets, high pre-training costs, limited context length, and prompt brittleness. On the other hand, the applications of LLMs span various fields, such as chatbots, computational biology, computer programming, and law. The paper aims to provide a systematic set of open problems and application successes to help machine learning researchers understand the field's current state more quickly and become productive.
That’s it for this week!
If you made it this far, drop a “Hi!👋🏽” in the comment section below. I wanna know who you are!
Cheers,
Harpreet