


How to fine-tune LLMs, a crash course in LlamaIndex, and how to speed up LLM inference
Plus news headlines, how you can help us win an award, and paid opportunity to work with me

🧐 What’s in this edition?
📺 Recording of the Oct 20th Hacky Hour
🧨 Sign up for a live Diffusion Webinar with me!
🗞️ The Sherry Code (News headlines)
🦙 A Brief Crash Course in LlamaIndex
📰 The Deci Digest (Research and repositories)
🏎️ How To Speed Up LLM Inference
What’s up, Community!
In case you missed it, we had a great technical session earlier today featuring one of our community members, Vasanth.
Vasanth explored the recent strides in Natural Language Processing (NLP), spotlighting the evolution from OpenAI's GPT-3 to GPT-4 and delving into the architecture of Large Language Models (LLMs).
He explained attention mechanisms in query analysis, introducing group query attention and Variable Group Query (VgQ) attention, notably enhancing model performance.
In particular, he discussed the DeciLM model, emphasizing its speed and cost efficiency compared to other models like Llama 2, 7 billion. Vasanth also shared insights on fine-tuning models using the Hugging Face platform, stressing the importance of large datasets, especially when employing LoRA for fine-tuning. Furthermore, he outlined the essentials of model quantization and device allocation for efficient model loading and utilization.
Lastly, Vasanth ventured into efficient training and optimization techniques, underlining the significance of certain settings and using LoRA adapters to achieve better performance with fewer trainable parameters.
If you’re interested in learning LangChain, then checkout Vasanth’s playlist on YouTube for several great, hands-on projects!
You can get the code for the session here.
Paid opportunity to work with me: If you're interested in freelance technical writing or blogging opportunities, email me with examples of your work. This quarter, I have a lot of content planned but not enough time to create it all.
So, I'm looking for talented, creative, and knowledgeable writers to help bring these ideas to life.
If that’s you, let’s get in touch!
🧨 LIVE Webinar: Optimizing Diffusion Model Deployments: Tips, Tricks & Techniques
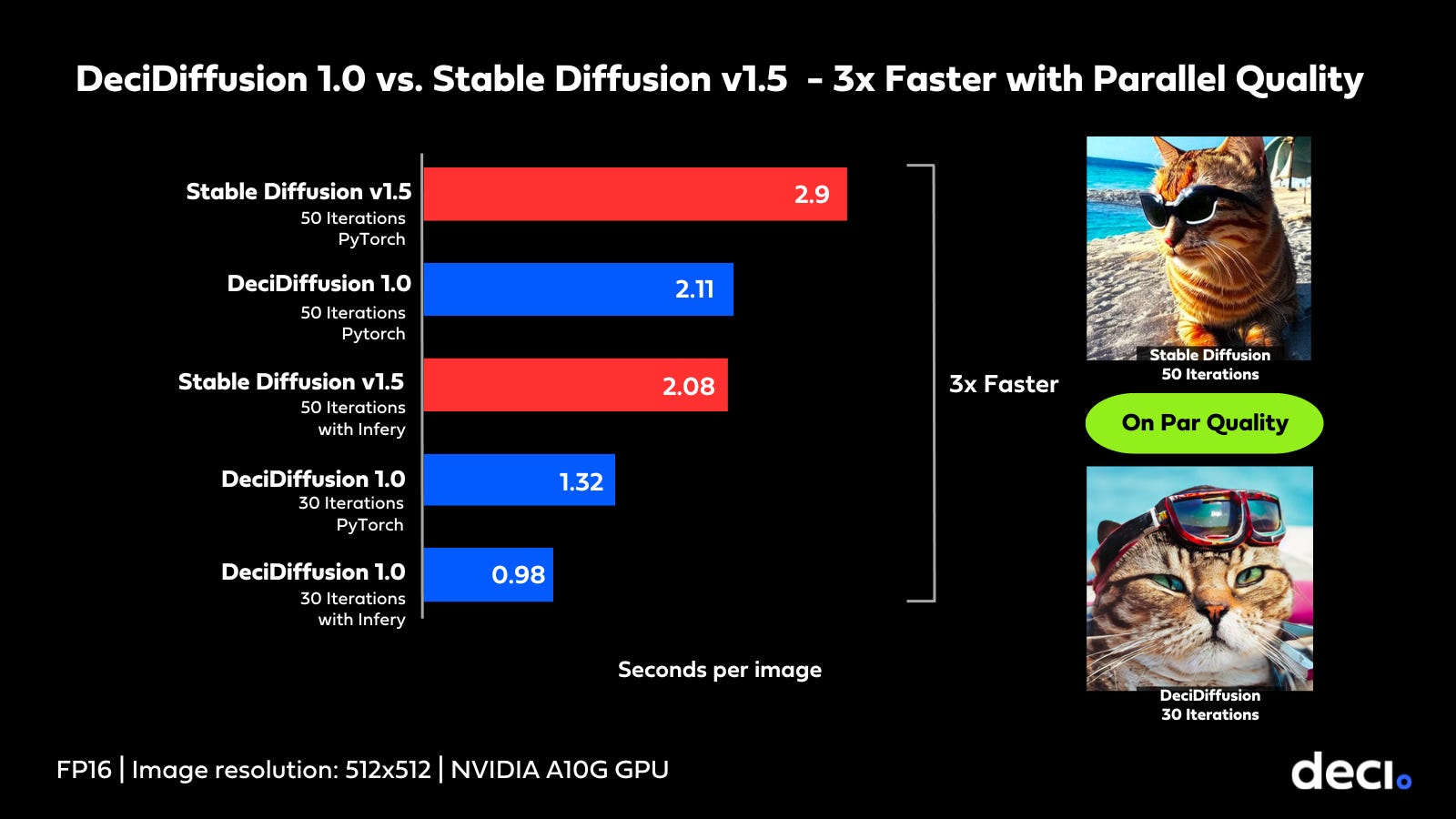
Join me, Harpreet Sahota, for a dive under the hood of DeciDiffusion—a model that delivers a staggering 3x boost in speed over Stable Diffusion with on-par quality.
Here’s the agenda:
Introduction
Overview of latent diffusion, Stable Diffusion 1.5, challenges with SD 1.5
Technical Deep Dive
DeciDiffusion’s Architectural Innovations
Training and Image Generation Techniques
Performance and Evaluation
Efficiency Gains and Quality Advantages
User Studies, Benchmarks, and Feedback
Practical Insights
See DeciDiffusion in Action
🗞️ The Sherry Code: Your Weekly AI Bulletin
Shout out to Sherry for sharing her top picks for the AI news headlines you need to know about!
Sherry is an active member of the community. She’s at all the events, shares resources on Discord, and is a fantastic human being.
Show some support and follow her on Instagram, Twitter, and Threads.
🍂 Taking a Leaf from the Past: 18th-Century Math Simplifies Modern Deep Learning: Researchers unearth a golden nugget from the 18th century to simplify the complex landscape of deep learning, ushering in an era of greener and more user-friendly AI solutions.
🚀 Nvidia's Jetson Platform: The New Horizon of Computer Vision: Nvidia turbocharges the Jetson Platform, opening doors to a full-fledged computer vision platform poised to revolutionize many applications.
👁️ Vision Language Models on a Diet: Smaller, Faster, Stronger with PaLI-3: A groundbreaking paper unveils PaLI-3 Vision Language Models, epitomizing efficiency and power in computer vision, making models smaller yet more robust.
🇨🇳 The Pinnacle of Pattern Recognition: Highlights from PRCV 2023: The 6th Chinese Conference on Pattern Recognition and Computer Vision (PRCV 2023) showcases many innovative papers, marking a milestone in the journey of computer vision.
🔬 Steel's Microscopic Tell-Tale: Deep Learning Deciphers Material Quality: Venturing into the microscopic realm, deep learning emerges as a game-changer in classifying steel microstructures, ensuring top-notch quality in rolling bearings, crucial for meeting industry standards.
🦙A Brief Crash Course in LlamaIndex
In this step-by-step tutorial, I show you how to perform retrieval augmented generation (RAG) with LlamaIndex and DeciLM.
LlamaIndex is a data framework for connecting custom data sources to LLMs, essentially a beneficial tool for users building LLM apps.
The State of AI 2023 Report recently came out, and I got curious: 𝐈𝐬 𝐢𝐭 𝐩𝐨𝐬𝐬𝐢𝐛𝐥𝐞 𝐭𝐨 𝐞𝐱𝐭𝐫𝐚𝐜𝐭 𝐦𝐞𝐚𝐧𝐢𝐧𝐠𝐟𝐮𝐥 𝐚𝐧𝐬𝐰𝐞𝐫𝐬 𝐮𝐬𝐢𝐧𝐠 𝐋𝐥𝐚𝐦𝐚𝐈𝐧𝐝𝐞𝐱, 𝐃𝐞𝐜𝐢𝐋𝐌-6𝐁-𝐈𝐧𝐬𝐭𝐫𝐮𝐜𝐭, 𝐚𝐧𝐝 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥 𝐀𝐮𝐠𝐦𝐞𝐧𝐭𝐞𝐝 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧?
The result?
I'm excited to share a hands-on tutorial on RAG using LlamaIndex and DeciLM involving the report—complete with techniques and best practices—with the community!
📰 The Deci Digest
I’m excited to share that Deci and the YOLO-NAS model have been nominated for @BigDATAwireNews Readers' Choice Awards 2023 in two categories, respectively:
• Top 3 Big Data and AI Startups
• Top 3 Big Data and AI Open Source Projects to Watch
The awards are based on readers' votes to determine the top big data products, projects, and services in 2023.
Help us win these categories: Vote for Deci and YOLO-NAS here (you can find us on items 10 and 11 )!
👨🏻🏫 How to Instruction Tune a Base LLM
Instruction tuning improves the capabilities and controllability of LLMs by fine-tuning a base model using pairs of instructions and their corresponding outputs.
This approach helps to align LLMs more closely with human instructions, making them more controllable, predictable, and adaptable without requiring extensive retraining.
The instruction tuning process follows a clear pipeline, which involves training a base model on instruction-output pairs.
This results in a more fine-tuned model that can better understand and respond to human instructions. This process allows LLMs to interpret human language better and produce more accurate and reliable outputs.
At a high level, it’s a two-step process:
Instruction Dataset Construction: Gather or generate instructions from existing datasets using LLMs.
Instruction Tuning: Fine-tune a base model with the assembled instruction dataset, ensuring they adhere more closely to human directives.
🏎️ How to Speed Up LLM Inference
The size and autoregressive nature of today’s large language models (LLMs) pose significant challenges for fast LLM inference.
Substantial computational and memory demands profoundly affect latency and cost. Achieving rapid, cost-efficient inference requires the development of smaller, memory-efficient models and the implementation of advanced runtime optimization techniques.
Watch the webinar for an in-depth exploration into the forefront of model design and optimization techniques. Discover strategies to accelerate LLM inference speed without sacrificing quality or escalating operational expenses.
What you’ll learn:
Explore efficient modelling techniques: Dive into techniques that enhance LLM efficiency while maintaining quality, including grouped query attention (GQA) and variable GQA.
Understand recent LLMs: Discover why recent LLMs, such as Llama 2 7B and DeciLM 6B, outperform older and significantly larger LLMs.
Uncover advanced optimization techniques: Learn about advanced runtime optimization strategies like selective quantization, CUDA kernels, optimized batch search, and dynamic batching.
That’s it for this week!
PAID OPPORTUNITY: If you're interested in freelance technical writing or blogging opportunities, email me with examples of your work. This quarter, I have a lot of content planned but not enough time to create it all.
So, I'm looking for talented, creative, and knowledgeable writers to help bring these ideas to life.
If that’s you, let’s get in touch!
Cheers,