

The New Deci AI Inference Platform, LLM Evaluations and Benchmarks, and NVIDIA GTC
Deep dive into what these benchmarks measure, what I'm most pumped about for GTC, and a few notebooks to get you started with the new platform

What’s up, Community!
🧐 What’s in this edition?
💻 NVIDIA GTC
📊 What Do LLM Benchmarks Mean?
🆕 The New Deci AI Inferece
📰 The Deci Digest (Research and repositories)
📹 New YouTube Tutorials
tl;dr: Deci just dropped a new model and an inference platform. Here’s a tutorial notebook for using the API and a notebook showing how to use it in LangChain! You can try the model directly in the playground here. It’s free, and no credit card is required to sign up!
Are you going to NVIDIA GTC?
The Deci AI team will be at Booth 1501 - come and say hi!
Deci AI CEO, Yonatan Geifman, is delivering a talk titled Can High Performance also be Cost-Efficient when it Comes to Generative AI? You can add this session to your schedule here.
Can’t make it to GTC but still want to watch sessions?
Below are some sessions that I find most interesting, which NVIDIA has made open for you. You have to register for the virtual event and add these to your schedule.
Customizing Foundation Large Language Models in Diverse Languages With NVIDIA NeMo
Rapid Application Development Using Large Language Models (LLMs)
Retrieval Augmented Generation: Overview of Design Systems, Data, and Customization
You can explore more Generative AI sessions here.
📊 What Do LLM Benchmarks Mean?
Evaluating LLMs is hard. For several reasons:
Difficulty assessing nuance, context, and reasoning
Variability and inconsistency in outputs
Lack of interpretability and explainability
Resource-intensive evaluation
Difficulty of evaluating open-ended generation
Overcoming these challenges is an active area of research involving developing better metrics, benchmarks, stress tests, human evaluation protocols, and transparency tools. However, evaluating LLMs remains fundamentally difficult due to their black-box nature and the open-ended nature of language generation.
Despite this, we still try because evaluating LLMs is important.
The way I see it, LLM evaluations can be divided into two categories:
Benchmarks
Vibe checks
Benchmarks gauge the LLMs overall performance on a dataset, while vibe checks are informal assessments performed manually by an AI engineer.
Vibe checks are subjective and difficult to compare across models, while benchmarks provide insights into the LLM's strengths, weaknesses, and performance compared to other models.
At least one pain in the ass about benchmarks is that…there are SO MANY benchmarks out there!
Some benchmarks evaluate the knowledge and capability of LLMs by rigorously assessing their strengths and limitations across a diverse range of tasks and datasets. Other benchmarks assess how well-aligned an LLM is - evaluating their ethics, bias, toxicity, and truthfulness. Some benchmarks evaluate the robustness of LLMs by measuring their stability when confronted with disruptions. There are risk evaluations that examine general-purpose LLMs behaviours and assess them as agents. There are even benchmarks for assessing an LLMs knowledge of domains as diverse as biology and medicine, education, legislation, computer science, and finance.
But, over the last year or so, the community has seemed to converge around what I call the “big six”.

These benchmarks, used to assess base LLMs, include ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. These are the ones you’ve seen on the Hugging Face Open LLM Leaderboard - which is powered by Eluther AI’s Language Model Evaluation Harness.
But, what are these benchmarks? What do they measure?
Each of these benchmarks serves a unique purpose in assessing different aspects of LLMs. Everything from reasoning, commonsense understanding, and knowledge acquisition to truthfulness, logical deduction, and problem-solving abilities.
ARC (AI2 Reasoning Challenge)
Released in 2018 by the Allen Institute for AI
Contains 7,787 multiple-choice science questions for grades 3-9
Measures an LLMs ability to reason and apply scientific knowledge
Important because it tests higher-level reasoning and knowledge beyond just language understanding
Pros: Challenging questions that require reasoning.
Cons: Limited to multiple-choice format.
HellaSwag (Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations)
Released in 2019 by researchers from UW, AI2 and others
Contains 70,000 multiple-choice questions
Measures an AI system's ability to use commonsense reasoning to complete descriptions of situations
Pros: Focuses specifically on commonsense reasoning.
Cons: Contains some ambiguous or subjective questions.
MMLU (Massive Multitask Language Understanding)
Released in 2021 by researchers from Stanford, DeepMind, Google and others
Contains ~16,000 multiple-choice questions from 57 topics including STEM, social science, humanities
Measures an LLMs multitask accuracy across a broad range of academic and professional subjects
Important because it comprehensively evaluates the breadth of knowledge
Pros: Very broad coverage of knowledge domains.
Cons: Answers can be answered via information retrieval vs. reasoning
TruthfulQA
Released in 2022 by researchers from UMass Amherst and Google
Contains 817 questions designed to probe truthfulness and ability to avoid false or misleading answers
Measures an AI system's factual accuracy and calibration
Important because it evaluates truthfulness, which is critical for real-world applications
Pros: Focuses on truthful answering, an important capability.
Cons: Relatively small dataset.
Winogrande
Large-scale dataset of 43,985 Winograd Schema Challenge (WSC) problems
Introduced in 2020 to more rigorously evaluate machine commonsense reasoning
Adversarially constructed to be robust against statistical biases in existing WSC datasets
Highlights that models may be exploiting biases rather than achieving true commonsense understanding
GSM8K (Grade School Math)
Released in 2021 by researchers from UC Berkeley, Google and others
Contains 8,500 high-quality grade-school math word problems
Important because it evaluates mathematical reasoning, a key component of intelligence
Pros: High-quality problems that test mathematical reasoning.
Cons: Focused only on math word problems.
For chat and instruction-tuned models, we have the Holy Trinity of evals.

These are interesting because they’re evaluating models on open-ended generation…and they’re evaluating the models in some interesting ways!
One of these interesting ways is the LLM-as-a-Judge approach. This leverages LLMs as judges to evaluate chat assistants based on open-ended questions. MT-bench and Chatbot Arena benchmarks show that LLM judges like GPT-4 can match human preferences with over 80% agreement. LLM judges complement traditional benchmarks and offer a cost-effective way to evaluate chat assistants.
LMSys Chatbot Arena
Uses a pairwise comparison approach where users chat with two anonymous models side-by-side and vote for the better response
Has collected over 240K votes across 45 models as of March 2024
Computes an Elo rating for each model based on the pairwise votes to rank them on a leaderboard
Pros: Crowdsourced diverse questions, tests real-world open-ended use cases, ranks models by human preference
Cons: Votes may be noisy/biased, expensive to run
AlpacaEval/ AlpacaEval 2
AlpacaFarm is a dataset of 52,000 instructions and demonstrations
Compares model outputs to a reference model using an LLM-based annotator
Provides a leaderboard ranking model by win rate over the reference
Pros: Fast, cheap, reliable proxy for human eval on instruction-following
Cons: Biased towards verbose outputs, limited to simple instructions, not comprehensive
MT Bench (Multi-turn benchmark)
Contains 80 high-quality multi-turn questions across 8 categories
Evaluates instruction-following, knowledge, reasoning, etc. over multiple turns
Provides a score for each model and is used alongside Elo ratings in the Chatbot Arena leaderboard
Pros: Tests challenging multi-turn abilities, provides category breakdowns, uses strong LLM judge
Cons: GPT-4 judge can make errors, especially on math/reasoning, limited to 80 questions
Now that we’ve reviewed what these numbers mean, the table I will show you will make more sense!
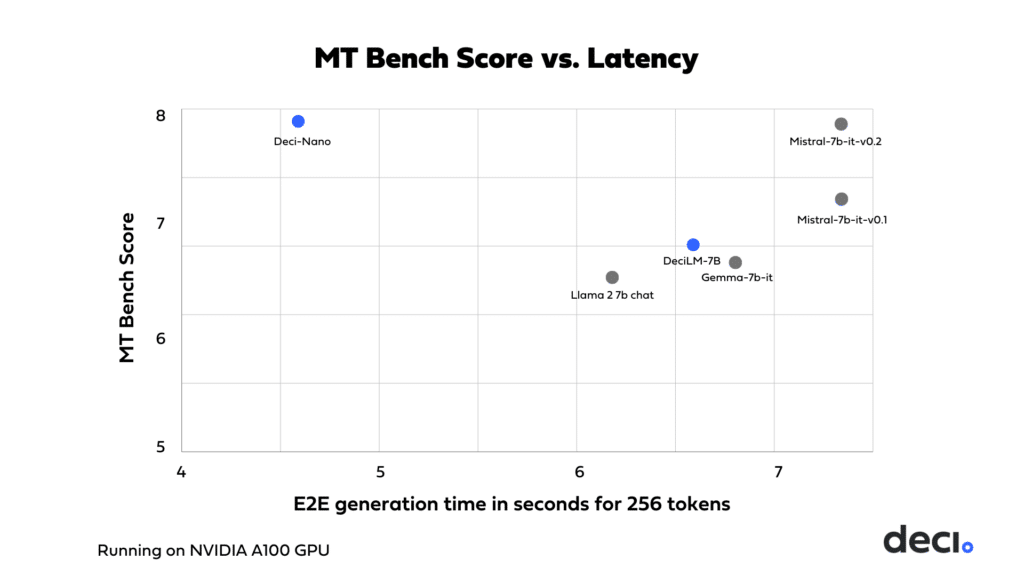
We just released Deci Nano and the Deci Generative AI Development Platform!
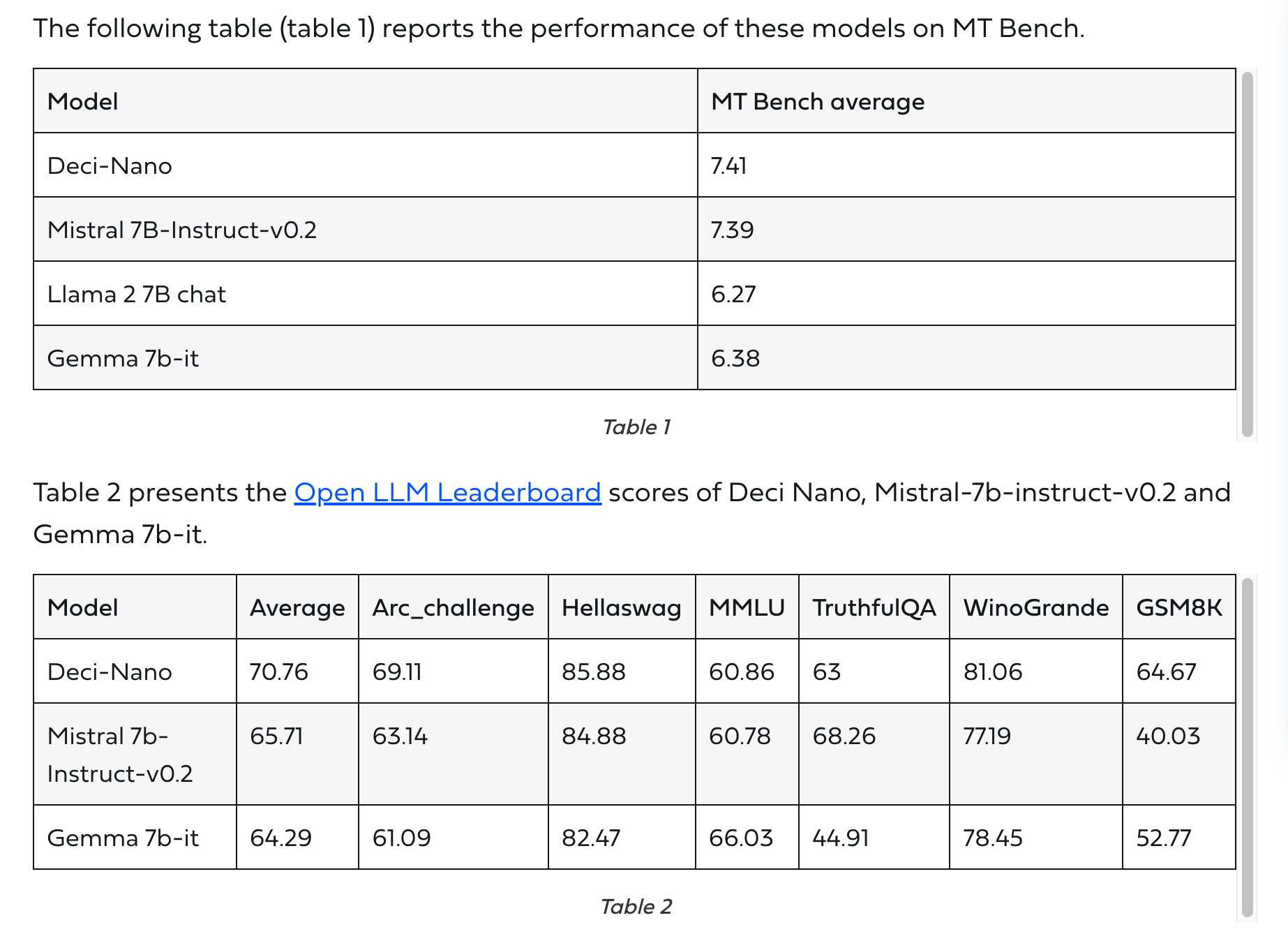
You can read more about the model and the platform here. It has amazing scores across all benchmarks and is blazingly fast!
You can try it for yourself in the playground here. Signing up for the API is free; no credit card is required. Enjoy!
More of a code-first type of person? Me, too!
Here’s a tutorial notebook which will walk you through using the API via cURL, requests, and the OpenAI SDK.
Here’s a tutorial notebook showing how to use it in LangChain.
And finally, a notebook showing you how to use the API along with LangChain and LangSmith
Happy hacking!
📰 The Deci Digest
👾 Google DeepMind has introduced Genie, which generates interactive playable environments from a single image prompt. The model has been trained on 2D games and robotic videos and shows potential for generalizability across domains.
🎬 Alibaba Research has published a paper on EMO, a framework for creating expressive videos from audio and image inputs. EMO uses a ReferenceNet network for feature extraction and a diffusion model for generating video frames.
📌 Pinterest engineers share lessons learned and best practices for unlocking AI-assisted development. Details include the opportunities, challenges, and successes the team encountered from the initial idea to the general availability stage.
🛠️ Microsoft has expanded Copilot with a wider range of Windows 11 settings adjustments and integrated plugins for services like OpenTable, Shopify, and Kayak.
🚗 As the development of autonomous driving continues to evolve, automotive developers are exploring ways to optimize their systems for better performance. One approach that has gained traction is tailoring smaller models to specific hardware. By doing so, developers can achieve greater efficiency and accuracy, which are crucial for successfully implementing autonomous driving technology.